欢迎来到本文档!
本文档旨在提供软件使用的具体教程,包括软件的整体介绍和各个功能模块的使用。如果您对软件的使用有任何问题或需要进一步的信息,请随时提问。我们将竭诚为您提供帮助!
[TOC]

软件主要分为四个界面:项目管理、模型设计、模型训练以及评估部署,用户可以通过在这些界面上进行切换从而实现相应的操作。
对于其他界面的操作前提是必须已有一个项目工程。用户可以通过进入项目二级界面创建新项目或打开已有项目。
右侧按钮四个按钮:
- 保存:保存整个项目
- 另存为:将整个项目另存为
- 关于我们:开发团队和版权声明
- 在线资源:访问提供的在线资源
弹出一个新建窗口,窗口内容包括:
项目名输入框:输入项目名
项目描述输入框:输入项目描述【可以选择不输入】
项目任务选择按钮:选择项目所属任务,包括图像分类(Image Classification),目标检测(Objection Detection),语义分割(Semantic Segmentation),其中,选择目标检测任务后需要选择具体算法,包括:Faster-RCNN、SSD、FCOS
项目路径选择框:选择项目保存路径
新建项目后会得到一个项目文件夹,文件夹名字为用户输入的项目名,文件夹下包括一个项目配置文件.gdlproject文件(用于打开项目)和一个项目文件夹project(存放项目使用过程的输出),即:
project_name(文件夹) |-- project(文件夹) |-- project_name.gdlproject(配置文件)
注意:每个项目下的文件请不要随意修改,避免加载项目时出错!
弹出一个文件对话框,默认显示目录为软件安装目录,文件过滤只显示“.gdlproject”文件;
选择已创建的项目,点击创建的项目文件夹下的“.gdlproject”文件加载项目。
软件根据任务类型,为用户提供了部分模型的快速开始,点击项目名称可对应下载并打开项目,打开后将自动跳转到模型设计界面。
注意:
加载软件提供的快速项目时,模型设计界面搭建的模型仅供展示使用,执行训练的模型为预训练模型;
快速项目中,训练界面仅可加载该项目所对应的预训练模型,支持修改模型版本或backbone;
快速项目中为您保存了超参数设置和对应的训练文件,您可以根据您的机器自行调整;
若您想自定义模型设计界面内容,请新建一个项目。
模型设计界面通过图形化的算子元件,进行神经网络的搭建与设计,并生成设计模型的代码进行后续的训练。
点击保存按钮,保存当前显示的设计页面,默认保存当前设计页面的内容到当前项目文件夹/project/models下;
保存设计页面后将得到一个与设计页面同名的文件夹,文件夹包含:
a) 一个模型结构文件.gm,名字与设计页面同名;
b) 一个宏模块文件夹macroblocks(如果设计页面存在宏模块);
保存成功后,弹窗提示。
点击另存为按钮,将弹出一个文件对话框,选择当前设计页面要保存的位置即可将当前设计页面另存。
点击打开按钮,将弹出一个文件对话框,对话框自动筛选.gm文件;
选择要打开的.gm文件,将得到一个设计页面,其中内容为.gm文件保存的图结构。
选中要剪切的元件,点击该按钮,选择的元件拷贝到剪切板上,并从其当前所在页面移除。
选中要复制的元件,点击该按钮,选择的元件拷贝到剪切板上。
将当前剪切板上拷贝的元件粘贴到当前页面上。
放大当前页面。
缩小当前页面。
在当前设计面板上,新建一个设计页面;
弹出一个输入框输入新建设计页面的名字(最好以要搭建的模型名字进行命名)。
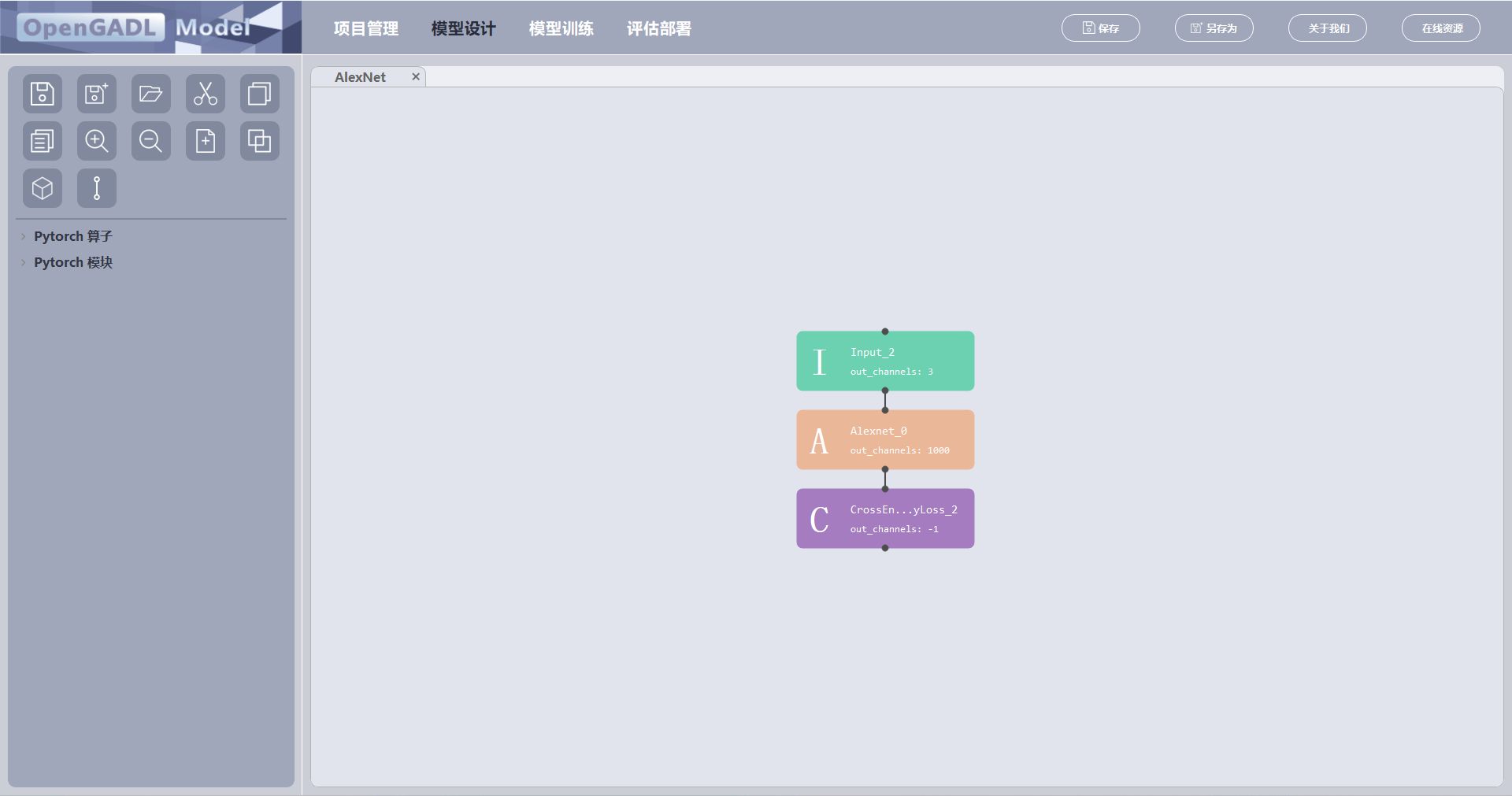
将选中的元件组合成一个宏模块,选中的元件移动到宏模块的子元件页面上:
首先,选中要组合的元件;
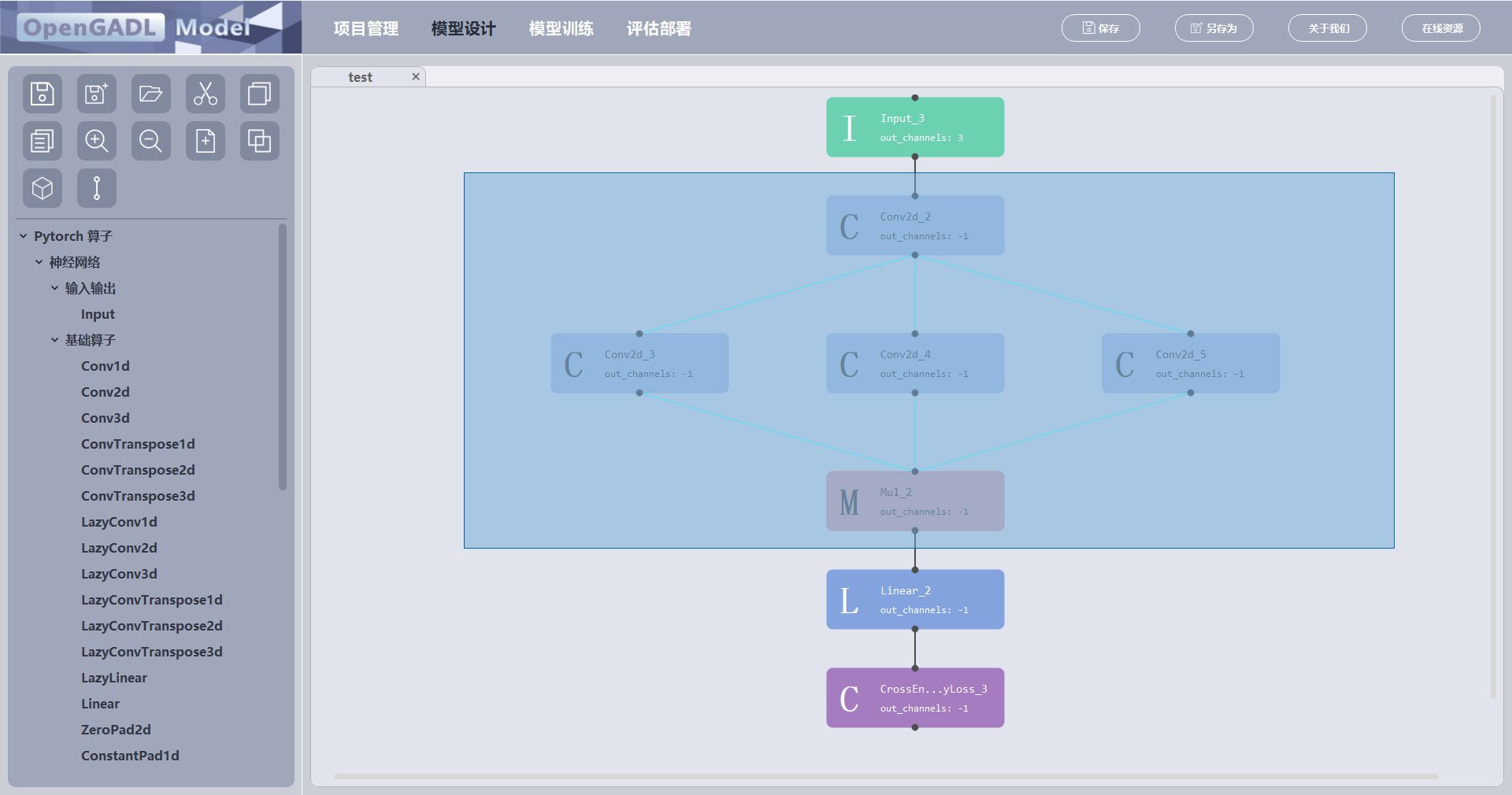
点击按钮,弹出一个输入框输入宏模块的名字;
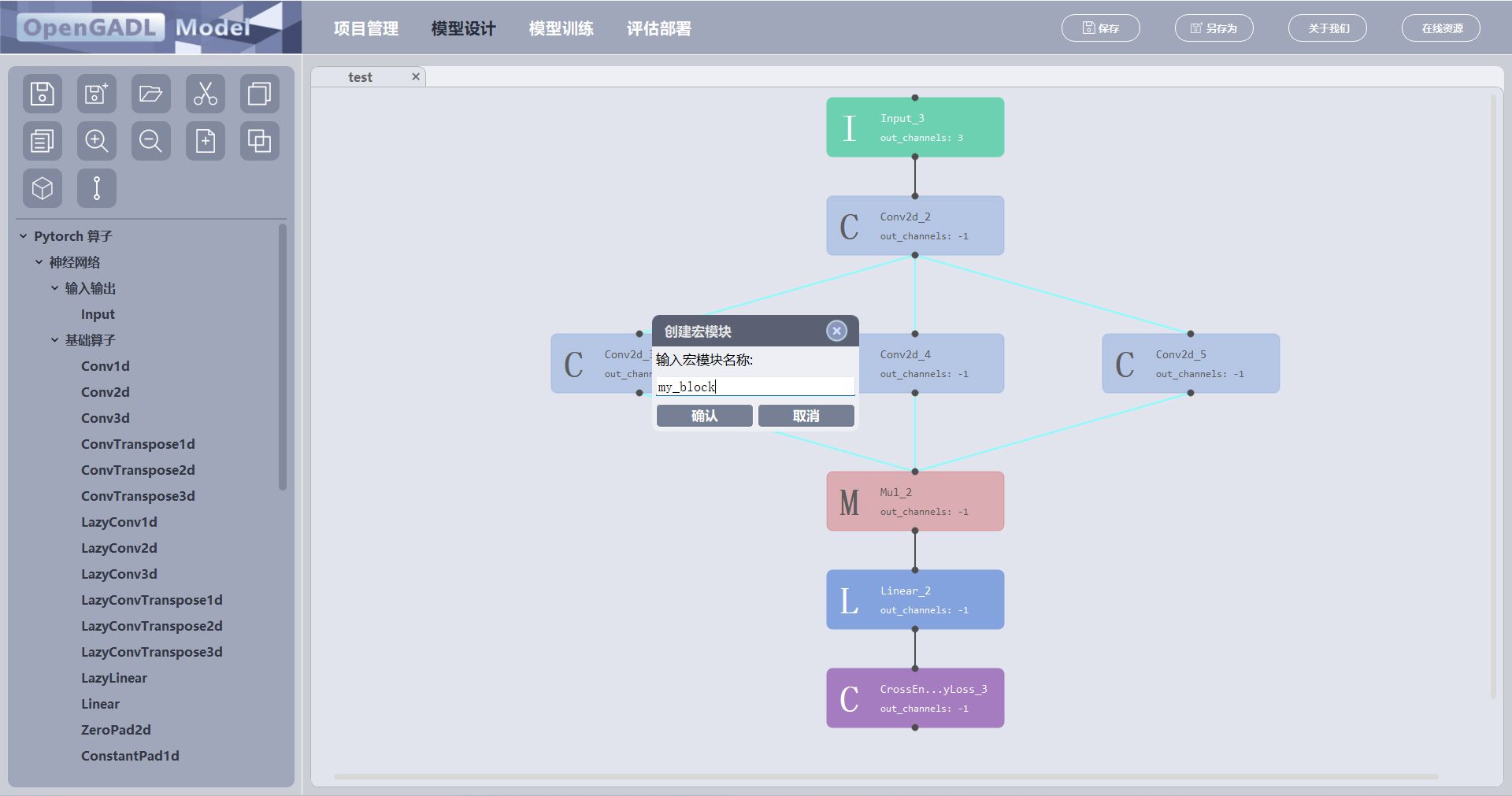
点击OK,成功创建宏模块“my_block";
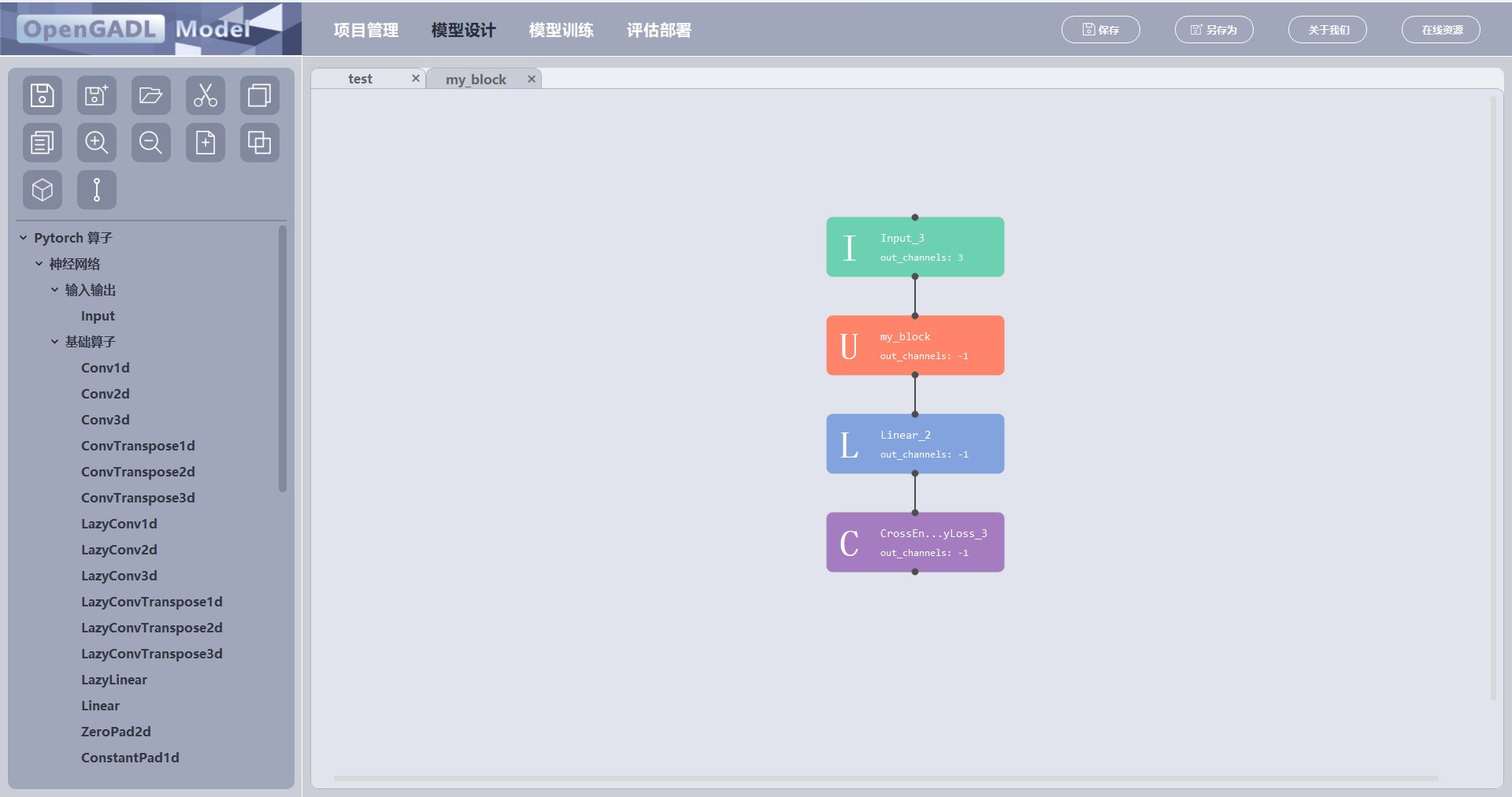
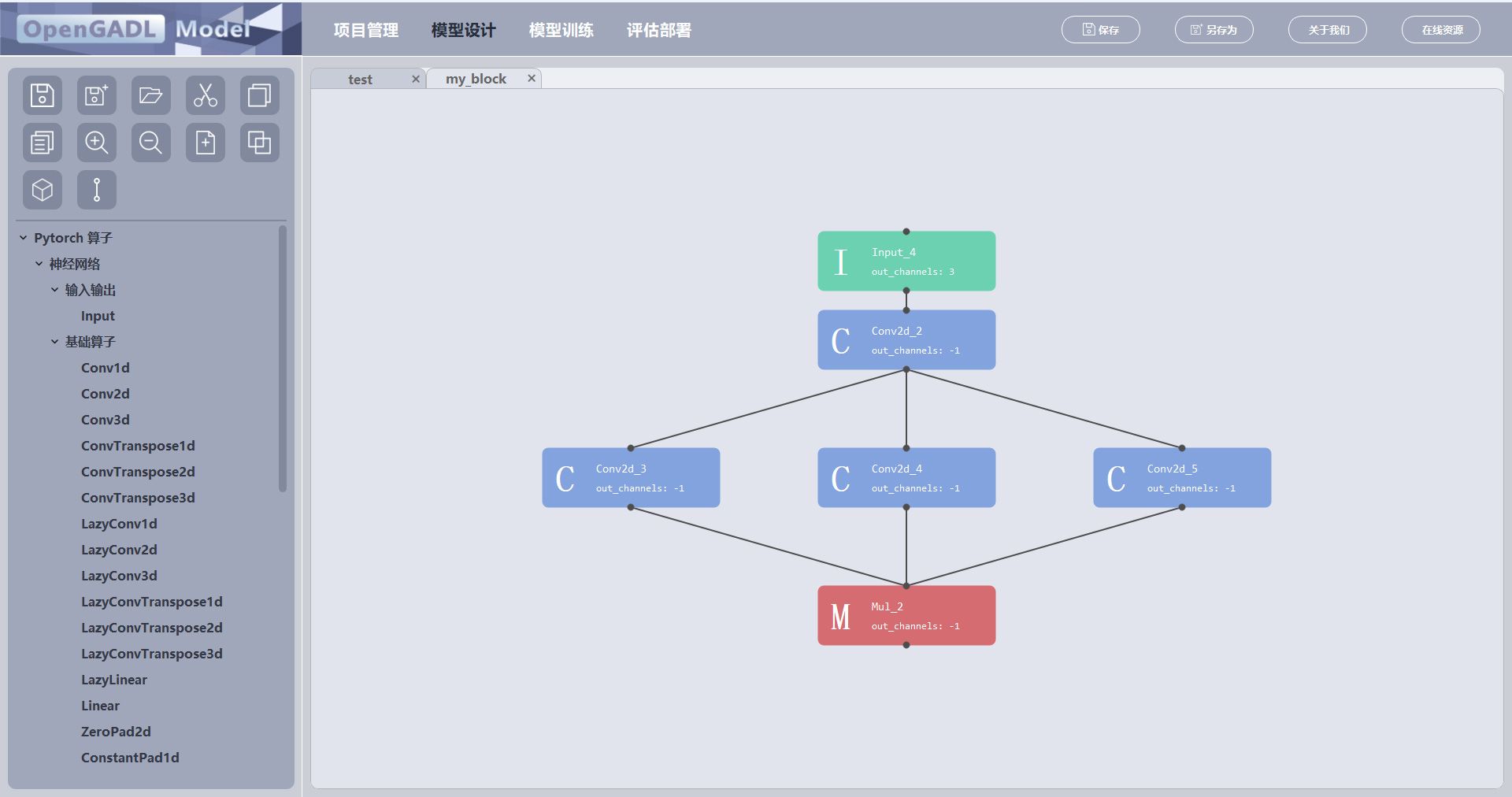
宏模块组合规范:
选中的元件只有一个起始元件和一个终止元件;
选中的元件之间都存在连接关系;
除起始元件和终止元件以外,选中的元件的相连元件也都是选中的。
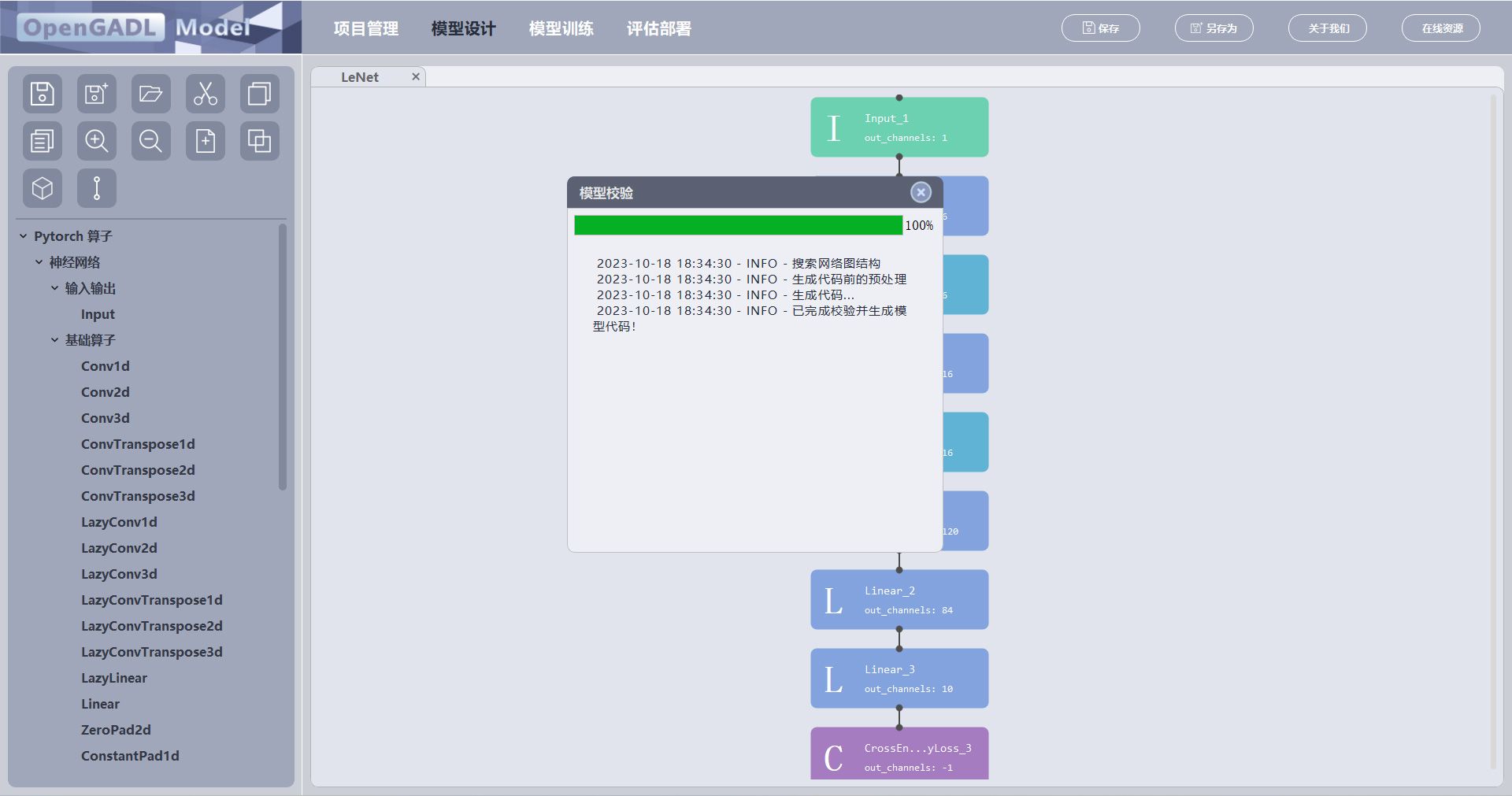
点击按钮,对当前页面设计的模型进行校验,校验内容包括:
每个元件参数配置页面配置的参数是否合法;
顶层模型设计页面是否包含Input算子;
顶层模型设计页面是否包含损失函数算子;
连接多个输入的元件是否合法。
校验失败,弹出窗口提示;
校验通过,根据输入给定输入尺寸,得到每个元件的输入尺寸和输出尺寸【通过唤醒元件的参数配置界面查看】;同时生成模型代码,存放在模型.gm文件同级目录下。
点击该按钮进入连线状态,再次点击该按钮或点击鼠标右键或按下键盘Esc键退出连线状态。
连线状态下,先选中连线的起始元件; 选中起始元件之后,起始元件保持选中状态;
然后选中终止元件,如果选中终止元件合法,即可完成起始元件到终止元件的连线;
连线始终从起始元件下方输出,连接到终止元件的上方;
如果选中终止元件非法,不绘制连线。
终止元件非法情况:
没有选中元件;
选中终止元件,但终止元件与起始元件相同;
选中终止元件,但终止元件与起始元件已有一条相同的连线。
元件列表包含所有可以添加到设计页面上进行模型设计的算子与宏模块;
通过点击要添加的元件,即可添加一个该类元件到当前设计页面上;
元件列表主要分为两类:算子和宏模块。
算子列表目前实现了pytorch.nn库下的147个算子,主要分类如下:
输入输出:输入算子Input;
基础算子:如卷积层,全连接层等;
池化算子;
激活函数算子;
损失函数算子;
批归一化算子;
随机失活算子;
循环神经网络和注意力机制相关算子;
其他算子。
分类如下:
软件预训练模型:包括分类、分割和检测模型;
用户自定义宏模块;
第三方模型模块。
模型设计面板展示每一个设计页面;
用户可在设计页面上通过添加、删除、拖拽、连接以及组合等方式对元件进行操作。
从模型设计页面左侧的元件列表中选择要添加的元件,鼠标左键点击元件名,即可添加一个该类元件到当前设计页面上。
鼠标左键点击页面上的元件即可选中元件。
选中元件后,按下键盘Delete键即可删除元件。
鼠标左键点击元件后不松开,移动鼠标即可拖动元件。
在设计页面空白处按下鼠标左键不松开,拖动鼠标出现一个选择框,进入框内的元件即被选中。
鼠标左键双击元件,即可弹出元件参数配置界面;
元件参数配置界面上可修改该元件的元件名以及元件的参数;
基础算子元件的常见配置参数包括:输入尺寸、输出尺寸、输入通道、输出通道、核大小、步长、填充等;
模型元件的常见配置参数包括:输入通道、输出通道、是否跳过全连接层、预训练模式等。
注: 宏模块的模块名也是通过参数配置界面上的Name进行修改的,并且模块名应该符合一定的命名规范:
只能以字母开头;
命名只能由字母、数字以及下划线‘_’组成。
双击设计页面标题,弹出输入窗口,输入新的页面名称,点击 “确认” 按钮,完成后点击 “模型检验” 按钮,检验通过后即可实现页面名称和模型名称的修改。
根据神经网络模型结构,从左侧元件列表中选择需要的元件,并在右侧区域进行排列;
根据数据传输顺序,使用 “连线” 按钮,将所有元件连接;
合并元件,构建宏模块(方便管理,可不选)。
根据神经网络模型结构,配置所有元件的参数;
注意:期间可通过 “检验模型” 按钮,定位错误位置并查看错误内容,辅助参数配置。
完成上述步骤后,点击 “校验模型” 按钮,完成模型搭建。
目前已实现的多输入算子
| 算子 | 作用 |
|---|---|
| Add | 对输入值进行数值上的相加 |
| cat | 对输入值进行拼接 |
| Mul | 对输入值进行相乘 |
其余算子均只接受单输入。
每个模型设计页面都需要至少有一个输入算子,作为模型输入的标识;
每个新建的页面会自动添加一个输入算子,每个组合的宏模块也会自动在输入端添加一个输入算子。
顶层模型设计页面(即非宏模块部分),需要在模型最后指定模型使用的损失函数,并进行连接。
鼠标左键点击预训练模型,即可添加一个模型元件到当前设计页面上,可将其作为独立的元件进行输入输出,并对其相关参数进行修改,但无法进入模型内部;
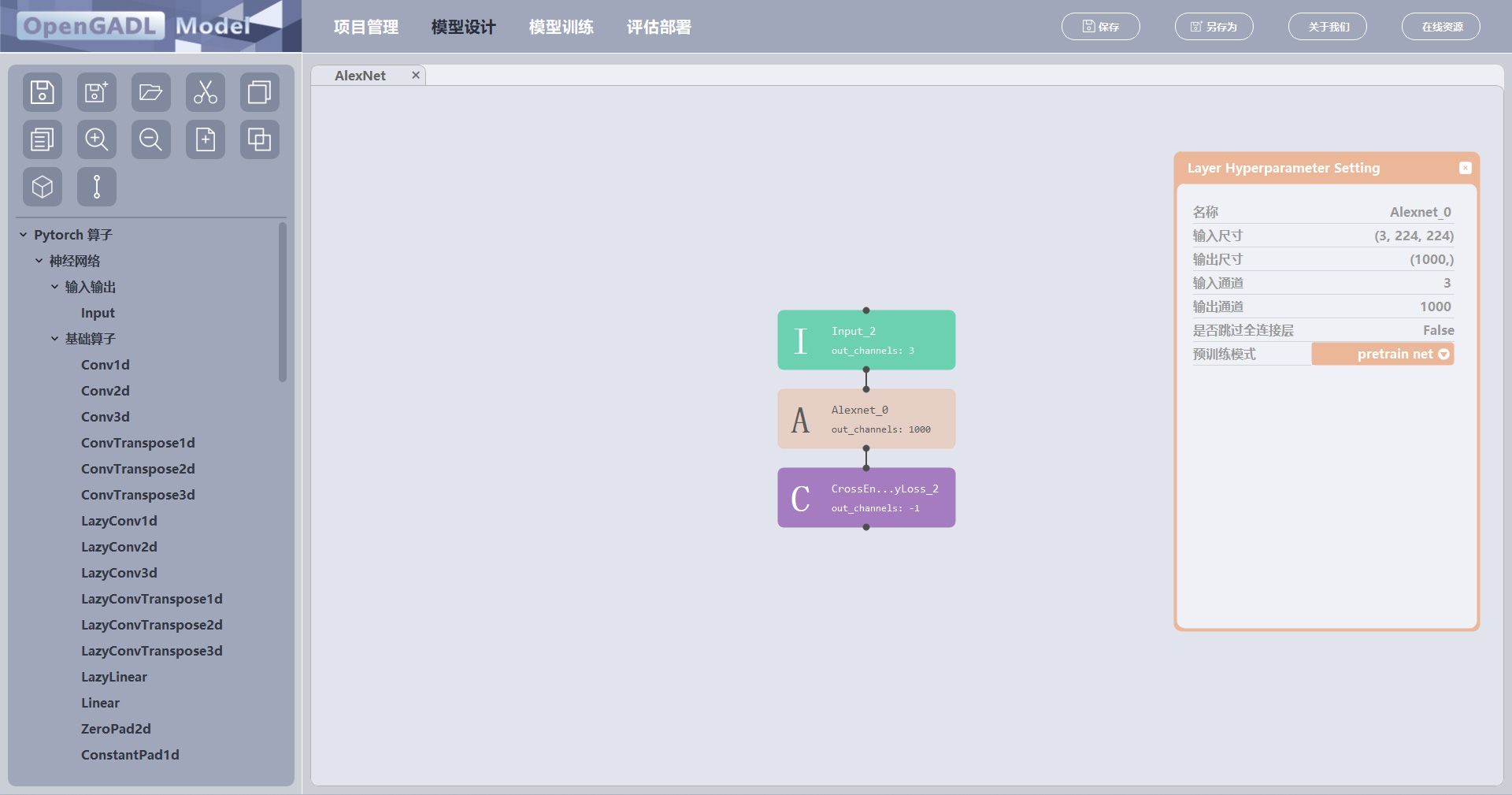
预训练模型元件参数:
- 名称: 模型名称,用于唯一标识
- 输入尺寸: 输入数据尺寸,不可修改,取决于该元件前一个元件的输出
- 输出尺寸:输出数据尺寸
- 输入通道: 输入数据通道数,不可修改,取决于该元件前一个元件的输出
- 输出通道:输出数据通道数
- 是否跳过全连接层:bool,是否跳过全连接层,只进行特征提取
- 预训练模式: 加载方式,选择是否加载预训练权重(分割和检测网络还可选择只加载backbone的权重)
用户创建宏模块后,可选择将其保存,便于后续使用;
鼠标置于所创建的宏模块上,点击右键,选择 “添加到自定义模块”;
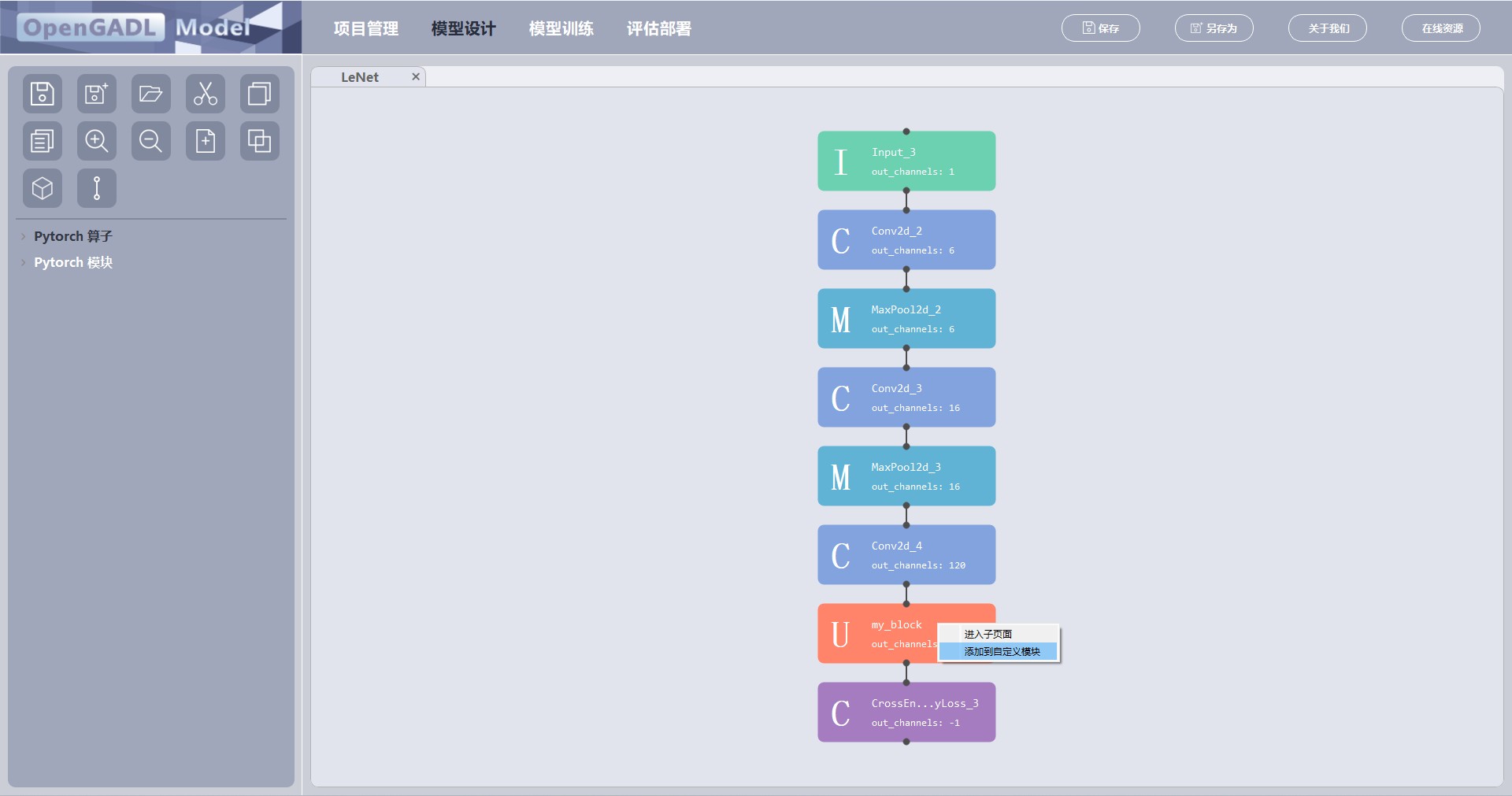
在弹出的对话框中填入宏模块名称、宏模块描述(可不填),点击 “添加” 完成保存,保存后左侧【Pytorch模块—用户宏模块】列表中会显示所保存的宏模块名称。
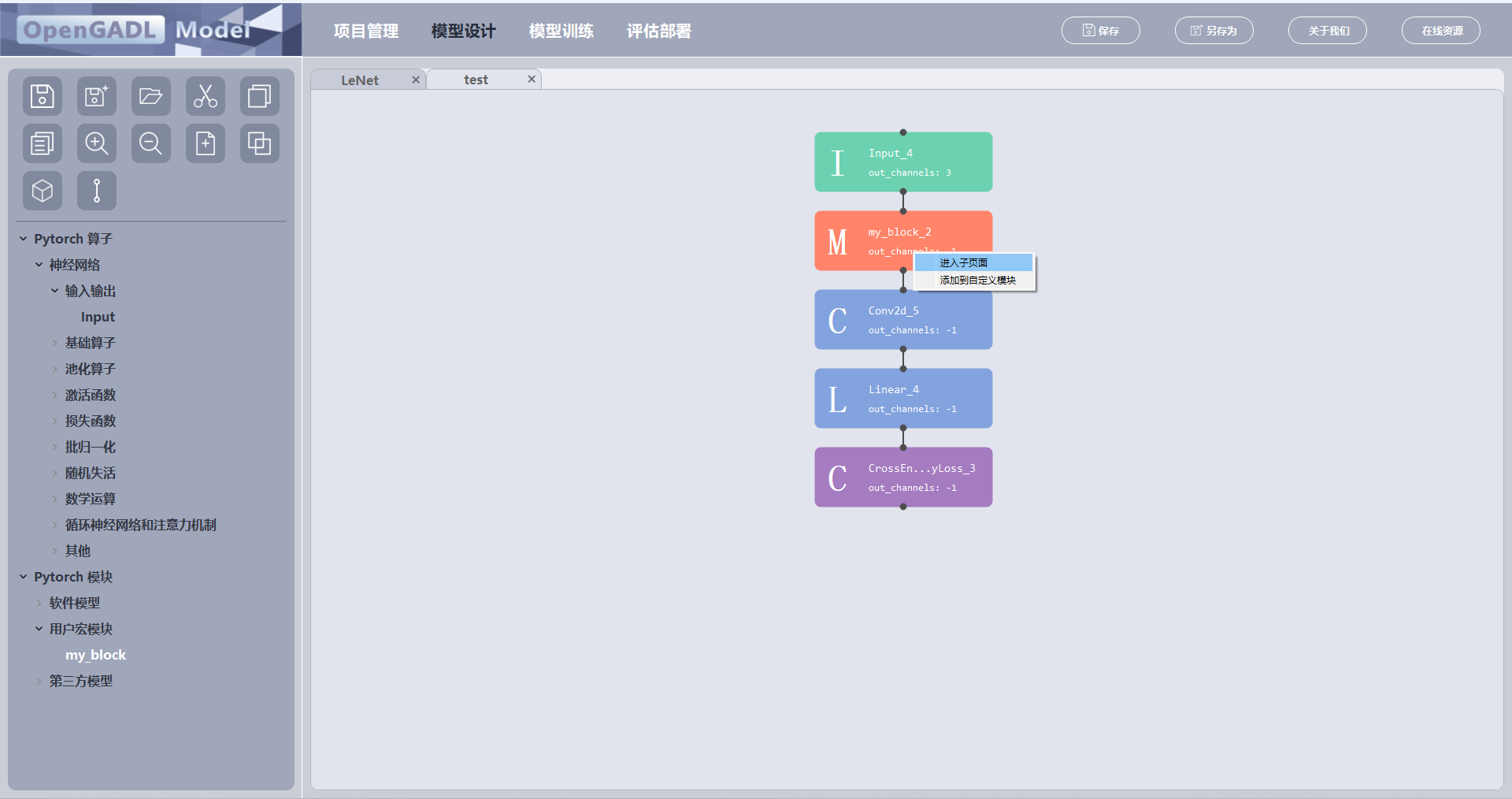
鼠标左键点击宏模块名,即可添加一个宏模块元件到当前设计页面上,可将其作为独立的元件进行输入输出;
鼠标置于所创建的宏模块上,点击右键,选择 “进入子界面” 进入宏模块页面,可对宏模块进行修改。
软件支持用户上传自定义模型、第三方模型:
在算子元件列表中选择【Pytorch模块—第三方模型—ThirdPartyModel】,添加到右侧界面中,同时添加输入算子和损失函数算子,并连线;
双击该算子元件,在参数配置界面中上传自定义或第三方模型文件(.py)和对应的权重文件;
点击 “模型检验” 按钮,完成自定义模型、第三方模型搭建。
点击按钮,在弹出的文件窗口中选择由该软件设计产生的模型文件夹(位于 “当前项目文件夹/project/models文件夹” 下)
软件提供两种选择数据集方式:
使用开源数据集:
目前软件提供MNIST,KMNIST,Cifar10和Cifar100;
用户选择 “使用公开数据集” 按钮,在下拉框中选择要使用的公开数据集。
使用用户自定义数据集:
自定义数据集需满足OpenGADL Model软件读取格式,推荐使用OpenGADL Data数据管理软件管理自定义数据;
选择 “使用用户数据集” 按钮,通过文件对话框选择您使用OpenGADL Data数据管理软件创建的数据集路径,实现对自定义数据集的加载。
不使用预训练模型:根据用户选择的模型从头开始训练;
使用系统提供的预训练模型:这些模型已经经过预训练,带有预训练权重;
使用用户提供的预训练模型:将导入用户提供的预训练参数到用户选择的模型文件夹中对应的模型,可提供续训功能。
使用CPU训练;
使用单个GPU训练,并指定使用的显卡序号;【若当前机器不存在GPU,下拉框中为空,无法使用GPU加速】
使用多个GPU并行训练,并输入使用的显卡(例:12,即使用编号为1和2的显卡并行)。
点击 【训练参数设置】 切换到参数设置子页面;
迭代轮次:配置训练迭代次数;
批量大小:配置每次训练每批数据的数据量;
保存间隔:配置保存checkpoint的频次(例:5,即每训练5个Epoch,保存一次checkpoint);
图像均值/图像方差:配置图像均值和方差;如果使用公开数据集,均值和方差已提供;如果使用私有数据集,可以默认保持全0值,软件将自动计算给定数据集的均值和方差【这可能消耗一些时间】;
优化器:配置训练使用的优化器,默认使用Adam。
点击 【数据预处理】 切换到数据预处理子页面;
该页面主要提供了一些对数据集进行预处理的功能;
选中处理策略前的按钮启用该策略,配置策略参数值。
除自定义配置参数训练外,软件提供了自动化训练功能,仅需要输入数据,根据训练偏向自动选择模型和训练超参数。
详情请参考4.1.2
详情请参考4.1.4
点击 【自动化训练】 切换到数据预处理子页面;
目标:用户训练偏向,共包含三个选项:高速度、高精度和均衡训练。
点击 “训练” 按钮,开始模型训练;
点击 “停止” 按钮,结束当前训练。
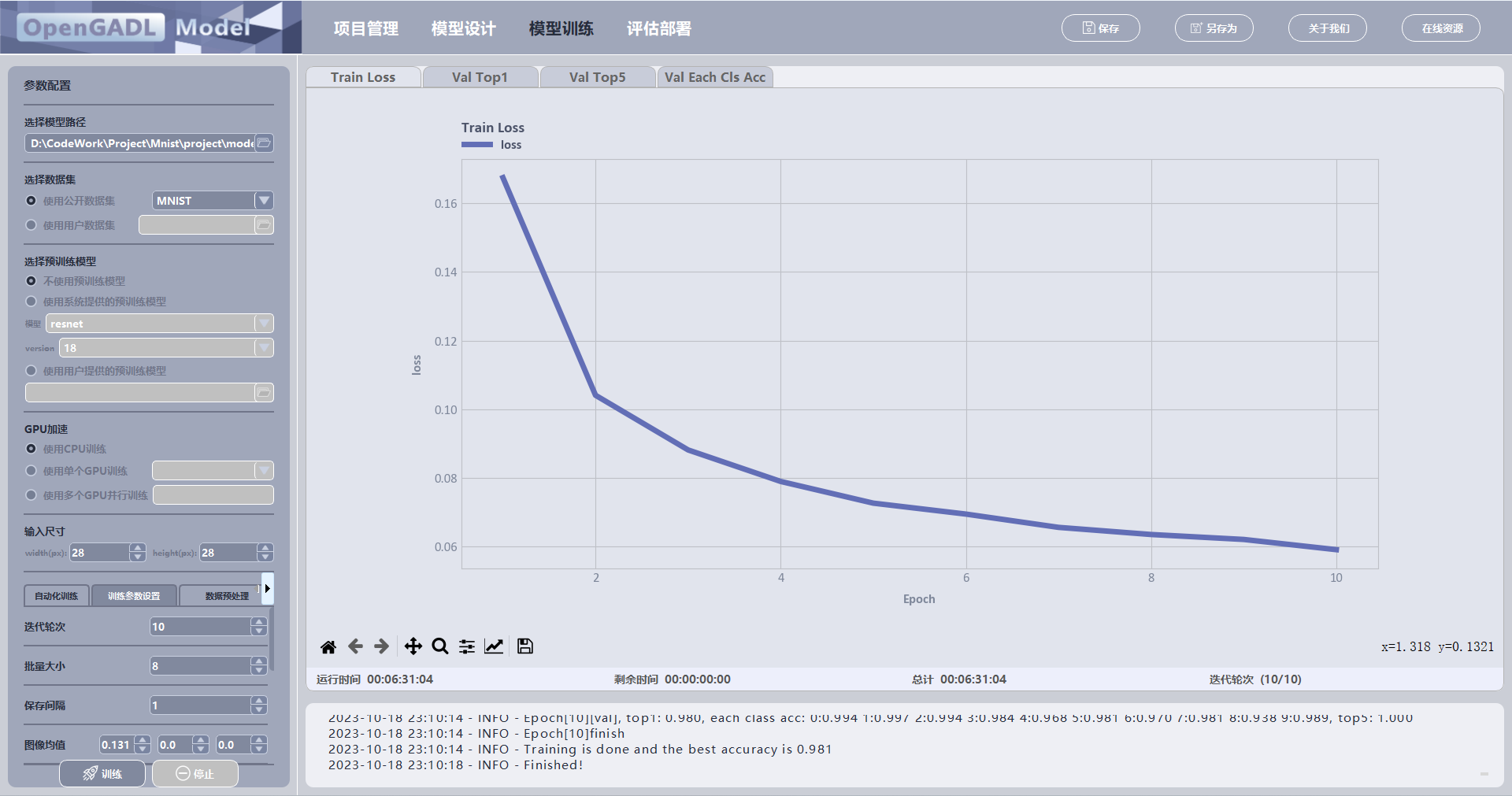
训练过程中在该面板上动态显示模型相关指标的变化情况;
对于分类任务,显示模型的训练loss变化,验证集top1变化,验证集top5变化(如果类别数大于5),验证集的每个类的准确率变化(类别数小于20)。
显示当前训练消耗时间,预计训练剩余时间,训练总时间以及当前迭代次数。
显示训练过程中输出的日志信息。
每次训练会在 “当前项目文件夹的project/train” 生成一个单次训练的文件夹,文件夹命名为:“训练的模型名 + 开始训练时间(YYYYMMDDHHmmSS)”;
单次训练文件夹包含两个内容:
训练脚本train.py
训练结构文件夹results,包括:
a) 训练面板显示的指标图文件夹imgs,生成指标图文件.png;
b) 训练权重文件夹weights,存放验证时的模型权重文件.pkl,保存频率由超参数Interval决定;
c) 训练日志文件train_log.log
软件提供了在原有训练基础上继续训练的功能,在每次训练结果文件夹中存在模型权重文件.pkl,或在模型文件夹中存在最佳模型训练权重,可通过加载原训练权重来实现模型的续训。
点击按钮,在弹出的文件窗口中选择您想要继续训练的模型文件夹。
略
选择 “使用用户提供的预训练模型” 按钮:使用用户提供的预训练模型,找到之前训练时所保存的权重文件。
略
略
略
点击按钮,在弹出的文件窗口中选择由该软件设计产生的模型文件夹;
软件会解析选定的模型文件夹下的权重文件(.pkl/pth),回显到下拉框进行权重文件的选择,从而完成用于测试的整个模型的选择;
权重文件命名:“模型名称_数据集名称_best_trained.pkl/pth”
选择测试数据提供两种选择方案:
选择单张图片:在本地选择一张待测试的图片,此时认为是对单张图片进行推理,即对一张无标签的图片做推理;软件将强制锁定测试batch_size为1。
选择数据集:在本地选择一个待测试的数据集,数据集应该符合软件数据集规范。
略
批量大小:
a) 如果选择的测试数据为单张图片,将强制锁定为1;
b) 如果当前项目任务为分割任务,将强制锁定为1;
c) 默认在训练结束后跟随训练界面的批量大小参数;
输入尺寸:设置测试的输入尺寸,默认在训练结束后跟随训练界面的input_size参数;
图像均值,图像方差:设置测试的图像均值和方差,需和训练的均值和方差保持一致,默认在训练结束后跟随训练界面的图像均值/图像方差参数。
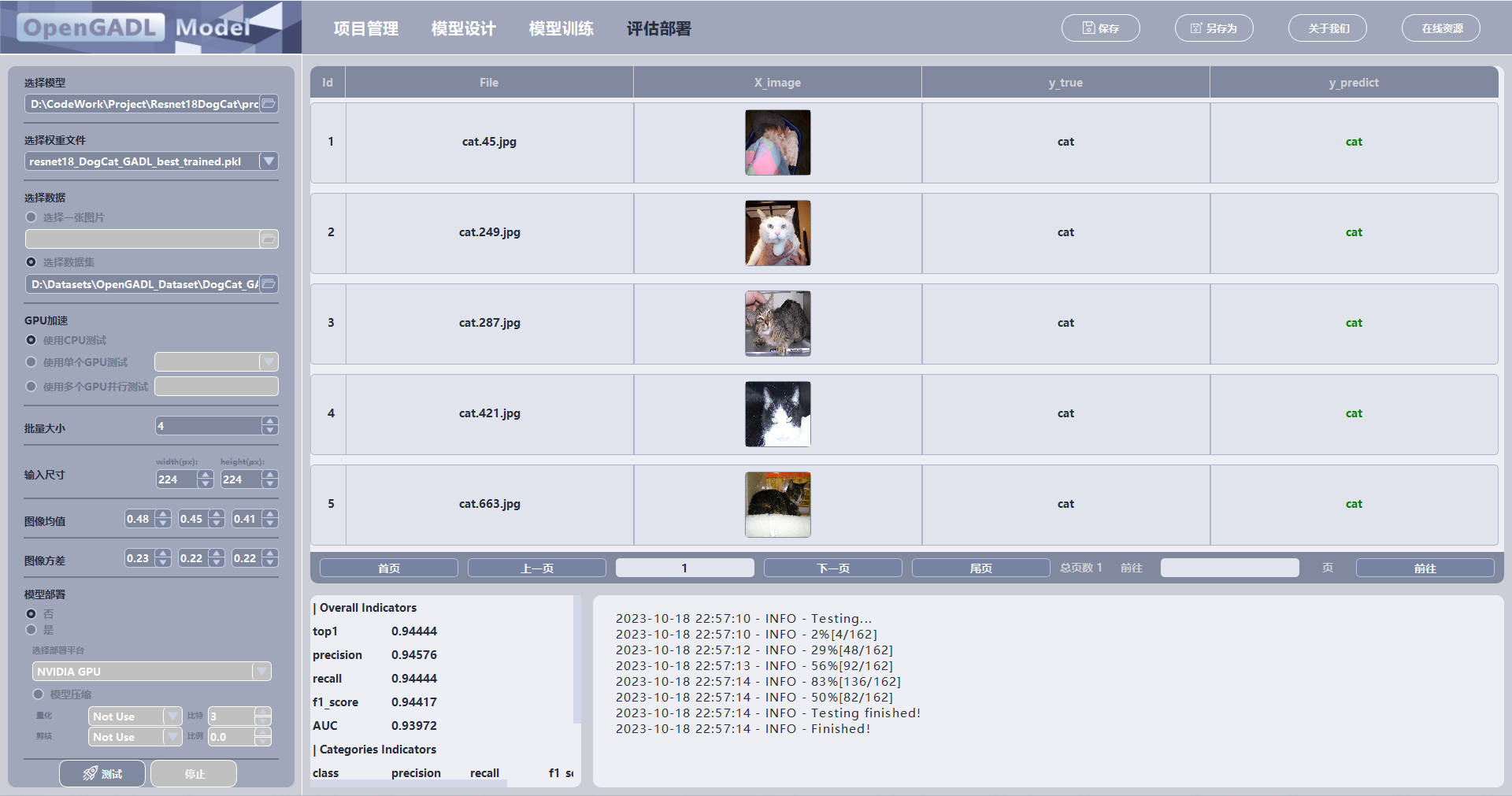
测试结束后在该面板上以表格的形式显示模型的测试结果。
1)测试结果表
以分页的形式显示所有测试结果,目前每一页显示5条数据的测试结果。
分页器功能包括:
切换到首页;
切换到上一页;
显示当前页;
切换到下一页;
切换到尾页;
显示总页数;
跳转到某一页。
对于分类任务,显示结果内容包括:数据序号(Id),文件名(File),原图像(x_image),标签值(y_true)【这一列取决于测试数据是否给定标签】,预测值(y_predict)【如果预测值与标签一致,预测值显示为绿色,否则显示为红色】
2)图像查看器
对于测试结果表中显示的图像,软件进行了压缩以固定尺寸显示在表格中;如果想查看图像的更多细节,可以单击表中图像,将弹出一个图片查看器显示图片原始尺寸,并可对图片进行放缩和旋转。
如果选定测试数据为一个数据集,测试结束后将生成对应的测试报告。
不同任务的测试报告内容如下:
| 分类 | 总体指标 | 准确率(precision) |
|---|---|---|
| 召回率(recall) | ||
| f1得分(f1_score) | ||
| AUC得分(AUC) | ||
| 各类指标 | 准确率(precision) | |
| 召回率(recall) | ||
| f1得分(f1_score) | ||
| 分割 | 总体指标 | 像素准确率(PA) |
| 平均像素准确率(MPA) | ||
| 平均交并比(mIoU) | ||
| 频权交并比(FWIoU) | ||
| 各类指标 | 各类像素准确率(CPA) | |
| 各类交并比(IoU) | ||
| Dice | ||
| 检测 | 总体指标 | 平均准确率(AP) |
| 阈值为 0.5 时,平均准确率(AP50) | ||
| 阈值为 0.75 时,平均准确率(AP75) |
显示测试过程中输出的日志信息。
每次测试会在 “当前项目文件夹的project/eval” 生成一个单次测试的文件夹,文件夹命名为:“测试的模型名 + test + 开始训练时间(YYYYMMDDHHmmSS)”;
单次测试文件夹包含测试结构文件夹bin,存储所有图片预测结果的npy文件。
在GADL 1.0发行版本中,部署模块置于【评估部署】界面,用户在该界面选择进行模型部署后,对应执行模型部署功能。
点击按钮,在弹出的文件窗口中选择由该软件设计产生的模型文件夹;
软件会解析选定的模型文件夹下的权重文件(.pkl/pth),回显到下拉框进行权重文件的选择,从而完成用于部署的整个模型的选择。
部署数据主要用于检测输入尺寸,以及在执行模型压缩时对模型的微调和校准;
选择部署数据集:在本地选择一个数据集文件夹,文件夹应该符合软件数据集规范。
略
选中模型部署按钮后,原界面 “测试” 执行按钮变为 “部署” 按钮,即当前执行模型部署功能
选择要部署模型的平台,主要包括:CPU、NVIDIA GPU、RSIC-V等平台。
不使用;
使用:包括模型量化(训练后量化,PTQ)和网络剪枝算法,可指定所使用算法、量化比特数以及剪枝率。
软件所支持的量化算法:MinMaxPTQ和MoveAvgPTQ;
软件所支持的剪枝算法:L1NormFilter、L2NormFilter和FPGMFilter。
每次部署会在 “当前项目文件夹的project/deploy” 生成一个单次部署的文件夹,文件夹命名为:“部署的模型名 + deploy + 开始部署时间(YYYYMMDDHHmmSS)”;
单次部署文件夹包含models文件夹,其中包含转换为onnx格式的网络模型。
GADL软件共支持两种类型数据的加载:公开数据集、用户自定义数据集。
软件对不同任务类型分别预置了公开数据集,您可以在训练界面,选中 “使用公开数据集” 按钮,选择该数据集以实现对该数据集的下载和使用,预置公开数据集包括:
| 任务类型 | 公开数据集 | 图片尺寸 | 数据集大小 | 类别 |
|---|---|---|---|---|
| 图像分割 | MNIST | 1×28×28 | 60000张训练图片,10000张测试图片 | 10 |
| KMNIST | 1×28×28 | 60000张,10000张测试图片 | 10 | |
| CIFAR-10 | 3×32×32 | 50000张,10000张测试图片 | 10 | |
| CIFAR-100 | 3×32×32 | 50000张,10000张测试图片 | 100 | |
| 图像分割 | VOCSeg | 3×513×513 | 1464张训练图片,1449张测试图片 | 21 |
| 目标检测 | VOCDet | 3×300×300 | 5717张训练图片,5823张测试图片 | 21 |
软件提供了加载自定义数据集的功能,您可以在训练界面,选中 “使用用户数据集” 按钮,通过文件对话框选中您的数据集文件夹。
自定义数据集需满足GADL软件读取格式,推荐使用OpenGADL Data数据管理软件管理自定义数据,利用该软件创建和标注的数据集可提供给GADL直接加载,具体加载步骤为:
使用OpenGADL Data软件创建并标注数据集,并将标注信息保存在用户自定义的目录下;
在OpenGADL Model训练/评估界面选中“使用用户数据集”,利用文件对话框选中在用户自定义目录中的数据集,点击“选择文件夹”按钮,实现数据集加载;
在配置完其他参数,执行训练/评估/部署时,软件会自动识别并读取所选取的数据集。
自定义数据集的文件夹结构:
- 数据集文件夹 - annotation文件夹 -- picture_1.json …… -- picture_n.json - config文件夹 -- categories.txt -- train.txt -- val.txt - SemanticSegmentation文件夹【图像分割数据集特有,以.png为例,也可以是.jpg等其他格式】 -- mask_1.png …… -- mask_n.png - images.txt - project_info.json
annotation文件夹下为包含所有图片的标签信息文件【图片名.json】,每个json文件的格式如下:
{ "info":{ // 描述标签信息字段
"description": "", // 标签描述
"contributor": "", // 标签作者
"date_created": "" // 创建日期
} "image":{ // 描述图像信息字段
"file_name": "", // 图像名
"width": 300, // 图像宽度
"height": 300, // 图像高度
"depth": 3 // 图像深度
} "classification":{ // 分类信息字段
"cls": "" // 类别
} "detection":[ // 检测信息字段
{ "bbox":[ , , , ], // 边界框
"category": "", // 类别
}
{ "bbox":[ , , , ], "category": "",
}
] "segmentation": 1 // 分割信息字段}键info:值dict[str: str],描述标签信息字段
键image:值dict[str: str],描述图像信息字段;;
键classification:值dict[str: str],描述图像类别;
键detection:值list[dict[str: list[float]/str]],描述图像每个目标的边界框和类别,用一个列表记录所有目标;
键segmentation:float,描述是否为分割任务;
config文件夹下包括包含数据集类别信息和数据集划分的txt文件;
SemanticSegmentation文件夹下为分割图像的mask图片;
images.txt中记录所有图片地址;
project_info.json中记录了数据集相关信息。
 联系邮箱:isbi@cqu.edu.cn
联系邮箱:isbi@cqu.edu.cn
 客服电话:18696936613
客服电话:18696936613
